This information source is open to the public, for personal study only, please do not use it commercially.
Part of the information content:
The application, management and display of data lake are integrated, providing standard services, data interfaces and report presentation methods. The data of data lake adopts efficient and reliable storage architecture. The enterprise business data migration plan is formulated, and the core data stored in ERP system, data acquisition system, OA system, video monitoring system and cloud business system are migrated to the data lake as a whole, and the inelastic resources are deployed locally. For the elastic computing function, it is necessary to cooperate with the algorithm data lake. So as to realize the controllability of core data and eliminate security problems and potential unknown risks. Support visual modeling, and support mouse dragging for artificial intelligence algorithm modeling. Including data preprocessing, feature engineering, algorithm model, model evaluation and deployment, etc., it supports many types of algorithm applications in the field of fast-selling business, including logistic regression, K nearest neighbor, random forest, naive Bayes, K-means clustering, linear regression, GBDT binary classification, GBDT regression and other algorithm models, and also supports artificial intelligence training models such as deep learning. The presentation layer displays the operation status and resource usage of various business systems in a multi-dimensional and dynamic way through unified business BI report components. And support the periodic or temporary generation of business situations, decision data display, fault analysis and mining and other business scenarios.
X x data lake architecture diagram
Document center:
It is mainly used to store files in various formats, including video files, video and audio files, PDF files, Office files and other types of files, and provides file-level full-text retrieval, document publishing, file sharing, file extraction and other functions. Provide file rights management, version management, version history recovery and other management functions.
The file content in the file center can exchange fusion data with the log center and data center through ETL process, and participate in data processing, data mining, machine learning, image analysis and so on.
Log center:
Collect all kinds of log data, IOT data and other real-time data, and the data will be processed in real time by the stream processing engine to ensure that the data will be analyzed and processed in the first time, so as to achieve real-time monitoring and real-time alarm.
The processed real-time data can be integrated with the data in the file center and data center to participate in data analysis.
Structured data center:
Real-time (or batch) access to structured data in databases or other media, and efficient processing of all kinds of data with the help of powerful processing capabilities such as Hadoop/Spark.
Effectively combine the data in file center and log center to participate in data analysis and data mining.
Support tens of billions of data Cube to achieve sub-second multi-dimensional query of massive data.
Standard SQL output interface, supporting the needs of continuous upgrading and secondary development.
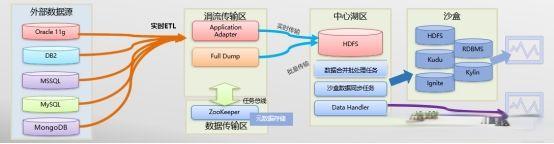 Schematic diagram of unified interface of data lake interface
Schematic diagram of unified interface of data lake interface
Data access principle
1. Give priority to the application-driven construction of high-value digital twin projects;
2. The data entering the lake must be certified by the data management department, and the corresponding data asset standards shall be issued to match the corresponding data responsible person;
3. The principle of data modeling is standardized step by step with original data, clean and integrated data, three normal forms structure and service wide table;
4. The overall platform shall conform to the principle of high availability and parallel expansion, and conform to the data planning of the business for 3-5 years.
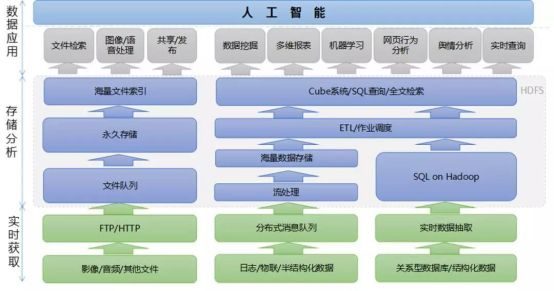
Real-time data synchronization supports most real-time database synchronization requirements. Support data synchronization across WAN and receiver clustering. Build a unified, standard, easy to copy and maintain data real-time synchronization platform, and at the same time complete the technical specifications and strategies of data real-time synchronization. Realize data synchronization monitoring system, and build a continuous and reliable real-time monitoring system for data update. Complete the integration mechanism of one-time rapid data import and incremental data import-trickle replication. The Full Dump module is used to realize the encryption of data warehousing, and the HiveSQL interface is provided based on Data Handle, at the same time, the decryption of data warehousing is completed. Control of data access rights through customization of Application Adapter.
L The scheme of keeping the original database for business systems that frequently read and write data, ERP system, data acquisition system, OA system, video monitoring system and cloud business system. Business data should be synchronized to the data lake, and the consistency between local data lake and business system data should be verified periodically during the parallel operation.
L receive real-time incremental data and store the data in the local data lake according to the predetermined architecture. Real-time production data is accessed in real time and reliably transmitted to the company’s database cluster. The data access amount is about 110TB/ day, and the historical data is 40000TB.
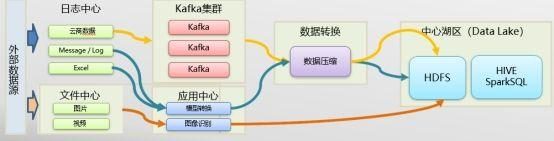
Logical architecture diagram of data migration
L Data lake operations are divided into two categories: inelastic and elastic. For inelastic operations, operations are performed in the local data lake. For operations that consume large resources and need elastic calculation, collaborative calculation is adopted with the enterprise cloud, and data is not saved in the enterprise cloud data lake. After the operation calculation is completed, the process and result data are sent back to the local data lake for storage. Interface service supports publish-subscribe mode, cross-data lake and cross-system call, HDFS, Hive, HBase and other systems.
A) interface type
Bulk data encapsulation
A large number of data are extracted according to certain conditions and packaged into data resources. Batch data packaging must be carried out through the system, not manually.
Data request interface encapsulation
The data is encapsulated as an access interface by restful interface, so that the accessor can access the data through remote call.
B) interface security
configuration management
Configure the content of shared data and sharing interface rules, including basic data configuration, sharing service configuration, sharing rights and sharing configuration distribution.
A) basic data configuration
It can configure the basic data used in the data sharing functional domain, including the configuration of the shared data system, the data structure and semantic description of the shared data entity, and the sharing method.
B) shared service configuration
Data service definition, data service directory, data service parameter configuration (such as: target system, sharing mode, data bearing mode, access frequency, access permission period), etc.
C) sharing permission configuration
Configure the permissions of the target system that is allowed to use the shared service, and support the permissions configuration of specific data entities and attributes within the shared service.
D) shared configuration distribution
The content of shared data and sharing interface rules are distributed to all relevant systems.
Data sharing process
Monitoring, exception handling and log management of data sharing processes, and providing query statistics and analysis functions for data related to data sharing.
A) table data sharing
The target system is an application layer analysis system, which directly opens the access rights of tables, and the target system extracts data through ETL.
B) data query
The target system is an application layer analysis system, and the target system directly calls the data query service provided by the data lake to complete the data query.
C) data subscription
The target system is an application layer analysis system, and the target system puts forward data subscription requirements, and the data lake provides data subscription services.


Space is limited, so it can’t be fully displayed. If you like information, you can forward it+comment, and learn more by private message.
关于作者